HTTP Request Smuggling via Unicode Payloads
Some libraries and applications including those used in older versions of NodeJS will convert Unicode characters into latin1 character sets by truncating the hexadecimal value representing each glyph so it fits in the 0-95 range for the basic latin character set, as well as with some control codes.
I've put together a little script that does the heavy lifting and will take a text file and generate a unicode payload here: https://github.com/Cameleopardus/latin1enctrunc_payload_generator
This bug was first reported in NodeJS Here: https://github.com/nodejs/node/issues/13296
If the puppy emoji gets translated to `=6`, I wonder if we could map out what characters translate into http control characters in latin1.

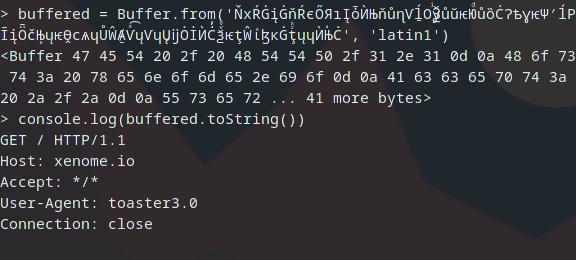
Interesting, we see the "c with carron" character translates to `0D` . Which when turned into a string will represent a carriage return.
The reason for this is that when implicitly transcoding to latin1, the unicode value for each character is simply truncated to fit.
the č character has a unicode value of U+010D, the unicode value of a carriage return is U+000D
the ů character has a unicode value of U+016F, if truncated the same way we get the letter o, which has a unicode value of U+006F.
If the http module used to send requests is implicitly converting Unicode characters into latin characters without escaping any of the data, we can inject a payload into a URL that when parsed and turned into an HTTP request would append an additional request to the body, which may be processed by the server as two separate requests.